本页内容
无需额外的脚本或第三方机器学习服务,一条带窗口函数的 SQL 即可为每个数据点计算异常分数。
监控与可观测性场景中有一类高频需求:从一条指标曲线里自动找出"突然异常"的点。常见的实现方式是把数据从数据库导出,交给 Python 脚本或独立的异常检测服务处理,算完再写回。这样的链路较长,也增加了数据搬运和维护成本。
GreptimeDB 1.0 内置了三个统计型异常打分函数,可以直接在 SQL 中为每一行数据计算异常分数。数据无需离开数据库,告警阈值就是一个 WHERE 条件。本文介绍这三个函数各自的原理、适用场景,以及如何把它们落地到一条可执行的查询中。
这三个函数是 anomaly_score_zscore、anomaly_score_mad 和 anomaly_score_iqr。它们都是窗口函数 (Window Function),必须配合 OVER 子句使用。
说明:这三个函数是 GreptimeDB 新加入的实验性 (Experimental) 函数,在后续版本中行为或签名仍可能调整,请结合所使用的版本查阅官方文档。
三个共同规则
无论使用哪个函数,以下规则都一致:
- 当窗口内有效(非 NULL)数据点不足时,函数返回
NULL。因此序列开头的若干行通常为 NULL,因为样本量还未达到要求。 - 分数
0.0表示该值不异常;分数越大,异常程度越高。 - 当窗口内的离散度(标准差 / MAD / IQR)为 0、而当前值偏离窗口中心时,函数返回
+inf,表示在一个完全平稳的窗口中出现的任何偏移都被视为无穷异常。如果下游系统不处理无穷大,建议在查询中过滤掉这类结果。
下面逐个介绍。
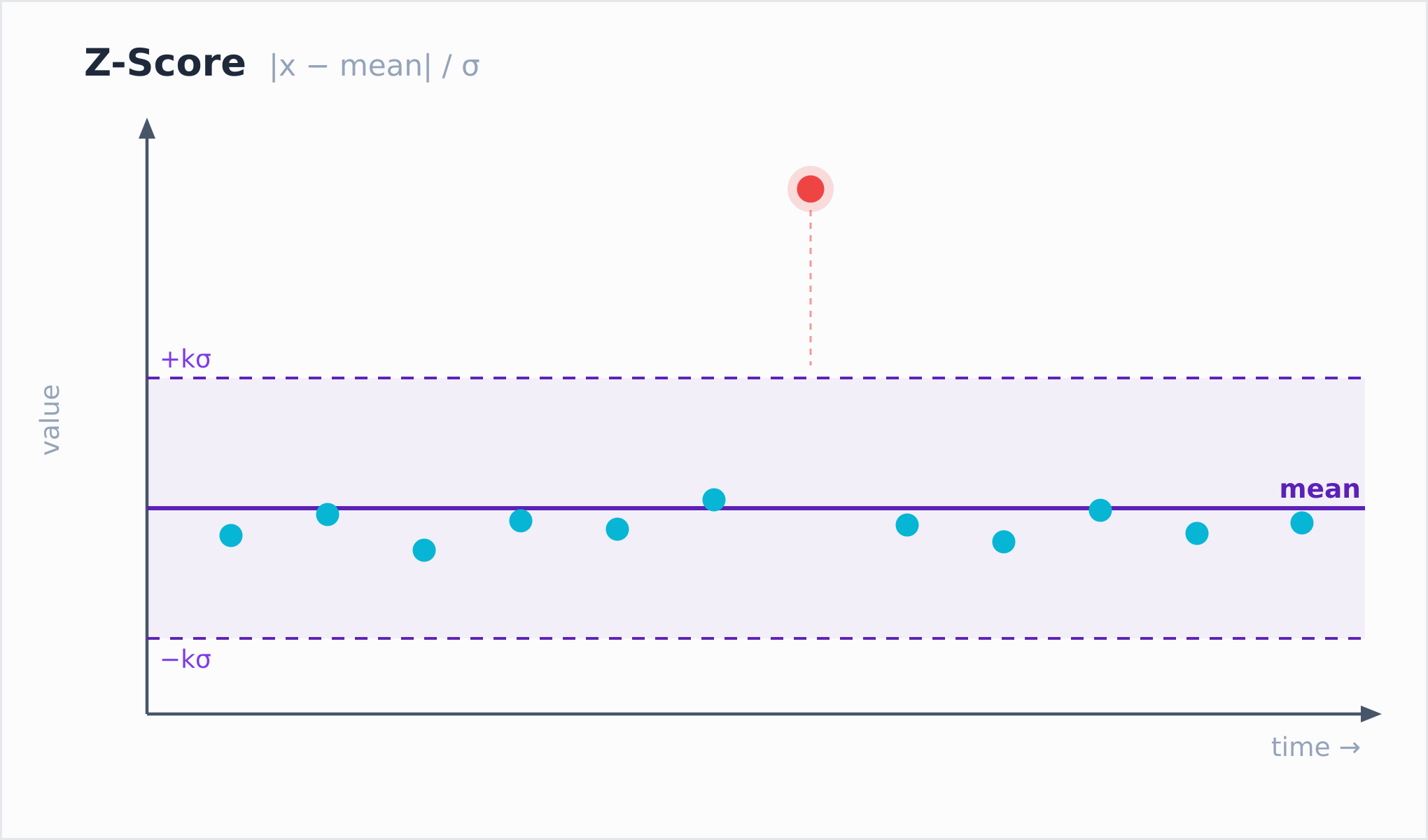
anomaly_score_zscore:直观但对离群点不鲁棒
Z-Score 是最经典的方法,公式也最直观:
score = |x − mean| / stddev即当前值偏离窗口均值多少个标准差,偏离越多,分数越高。
sql
anomaly_score_zscore(value) OVER (window_spec)它的最小有效样本数为 2(使用总体标准差,即除以 n)。少于 2 个有效点时返回 NULL。
Z-Score 的局限在于:均值和标准差都会被离群点本身影响。一个较大的离群值进入窗口后,会同时抬高均值和标准差,导致离群点稀释了自身的异常分数。这一现象在后文的完整示例中可以直接观察到:同一个离群点,Z-Score 只给出约 2 分,而另外两个函数给出了 100 以上的分数。
适用场景:数据本身较为干净、波动平稳,且只需要一个粗略的偏离信号时,Z-Score 计算最快,足以满足需求。
anomaly_score_mad:处理单点离群更鲁棒
MAD 即 Median Absolute Deviation(中位数绝对偏差)。它将 Z-Score 中的均值替换为中位数,标准差替换为 MAD:
score = |x − median| / (MAD × 1.4826)中位数对离群点不敏感——少量极端值几乎不会改变中位数,却会显著改变均值。因此 MAD 比 Z-Score 更鲁棒,更适合处理单点离群的场景。
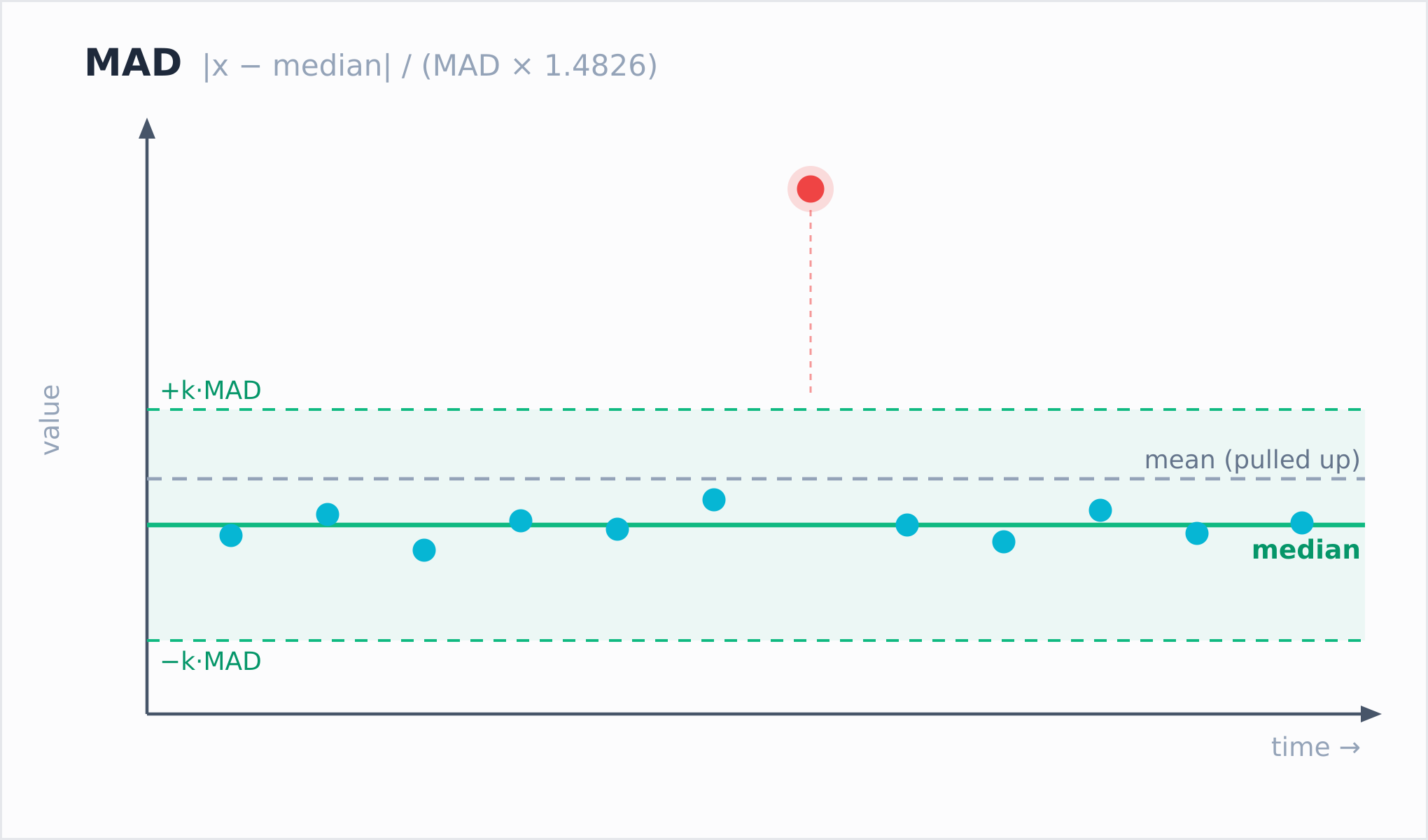
公式中的 1.4826 是一致性因子,作用是让 MAD 分数对正态分布数据渐近等价于 Z-Score。也就是说,在数据干净时 MAD 与 Z-Score 给出的分数接近,数据存在离群点时 MAD 才体现出优势。这一设计的好处是,在两个函数之间切换时无需重新校准阈值。
sql
anomaly_score_mad(value) OVER (window_spec)需要注意一个细节:MAD 的最小有效样本数为 3,比 Z-Score 多一个。原因是当样本只有 1~2 个时,MAD 几乎必然为 0,而 MAD=0 会触发前述的 +inf,从而产生大量无意义的"无穷异常"结果。将门槛提高到 3,正是为了避免这类虚假告警。
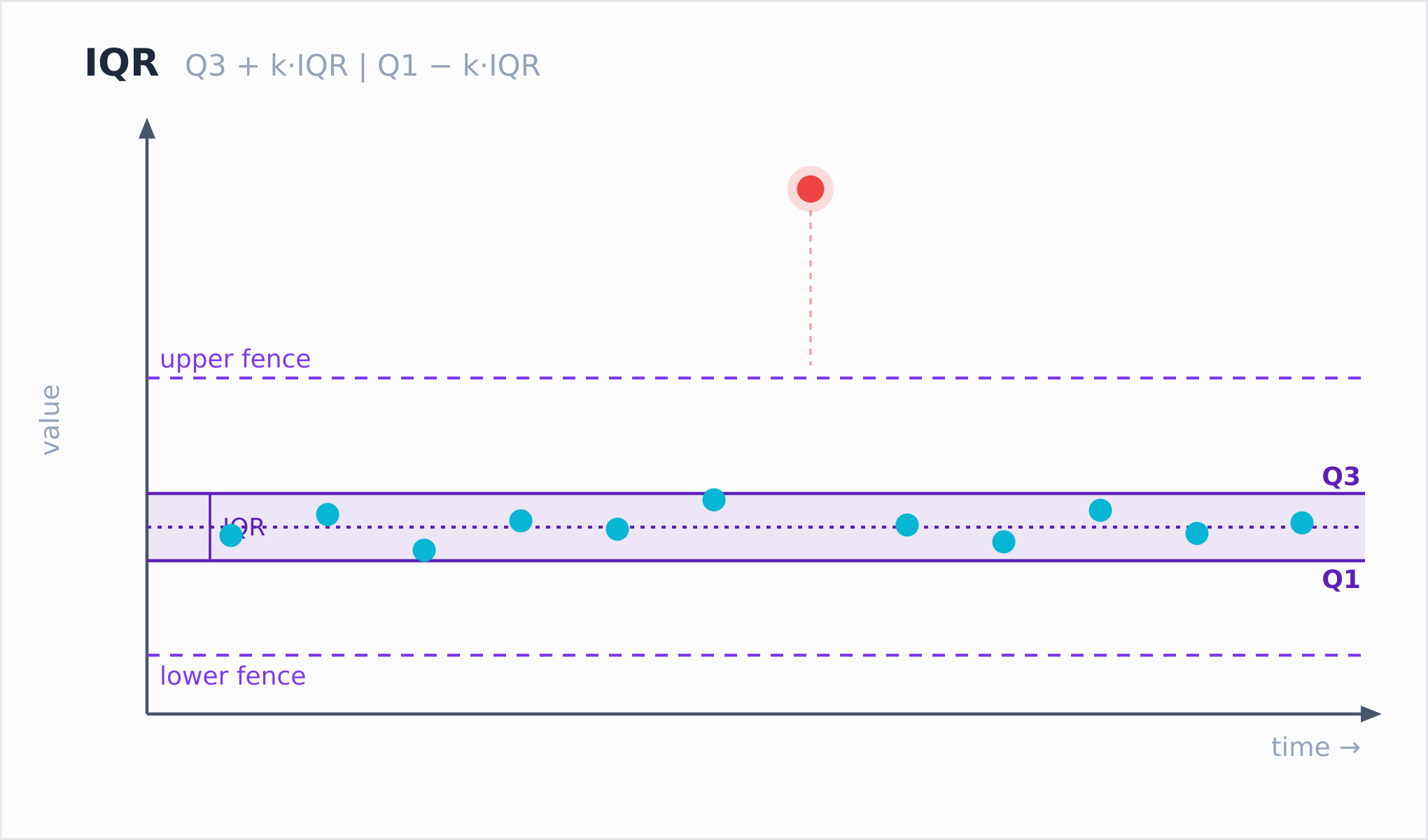
anomaly_score_iqr:支持可调阈值,适合告警
IQR 即 Interquartile Range(四分位距),对应统计学中的 Tukey Fences(图基栅栏)。它的思路与前两个函数不同:不计算"偏离中心多远",而是判断值是否越过栅栏,以及越过多远。
它比前两个函数多一个参数 k:
sql
anomaly_score_iqr(value, k) OVER (window_spec)栅栏定义为下界 Q1 − k×IQR 与上界 Q3 + k×IQR,打分规则如下:
- 值低于下界:
score = (Q1 − k×IQR − value) / IQR - 值高于上界:
score = (value − Q3 − k×IQR) / IQR - 值在栅栏之内:
score = 0.0
k 是一个非负 DOUBLE,用于控制栅栏的松紧。1.5 对应标准 Tukey 栅栏,3.0 对应更宽松的 far-out 栅栏。k 越大,只有越极端的值才会被标记;传入负数时函数返回 NULL。
IQR 的特点是天然适合告警:栅栏之内的值一律为 0 分,边界清晰,不会像 Z-Score 与 MAD 那样为正常值也算出零点几的小分。它的最小有效样本数同样为 3(在线性插值下,Q1≠Q3 至少需要 3 个点)。
适用场景:需要一个明确的"正常 / 异常"二分边界,并希望通过调整 k 来控制灵敏度,例如先用 1.5,若告警过于频繁则调到 3.0。
完整可执行示例
下面创建一张传感器表,写入一段平稳数据,并在中间注入一个离群点(80.0),然后同时使用三个函数。
sql
CREATE TABLE sensor_data (
host STRING,
val DOUBLE,
ts TIMESTAMP TIME INDEX,
PRIMARY KEY (host)
);
INSERT INTO sensor_data VALUES
('web-1', 10.0, '2025-01-01 00:00:00'),
('web-1', 11.0, '2025-01-01 00:01:00'),
('web-1', 10.5, '2025-01-01 00:02:00'),
('web-1', 10.8, '2025-01-01 00:03:00'),
('web-1', 80.0, '2025-01-01 00:04:00'), -- 离群点
('web-1', 10.3, '2025-01-01 00:05:00'),
('web-1', 11.2, '2025-01-01 00:06:00');三个函数使用同一个窗口定义。为避免重复书写,可以用 WINDOW 子句定义一个共享的命名窗口 w,并用 ROUND 将结果保留两位小数:
sql
SELECT
ts,
val,
ROUND(anomaly_score_zscore(val) OVER w, 2) AS zscore,
ROUND(anomaly_score_mad(val) OVER w, 2) AS mad,
ROUND(anomaly_score_iqr(val, 1.5) OVER w, 2) AS iqr
FROM sensor_data
WINDOW w AS (
PARTITION BY host
ORDER BY ts
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
)
ORDER BY ts;输出如下:
text
+---------------------+------+--------+--------+-------+
| ts | val | zscore | mad | iqr |
+---------------------+------+--------+--------+-------+
| 2025-01-01 00:00:00 | 10 | NULL | NULL | NULL |
| 2025-01-01 00:01:00 | 11 | 1 | NULL | NULL |
| 2025-01-01 00:02:00 | 10.5 | 0 | 0 | 0 |
| 2025-01-01 00:03:00 | 10.8 | 0.6 | 0.4 | 0 |
| 2025-01-01 00:04:00 | 80 | 2 | 155.58 | 136.5 |
| 2025-01-01 00:05:00 | 10.3 | 0.46 | 0.67 | 0 |
| 2025-01-01 00:06:00 | 11.2 | 0.38 | 0.67 | 0 |
+---------------------+------+--------+--------+-------+有两个细节值得关注。
第一,前两行的 mad 和 iqr 为 NULL,而 zscore 不是。这正是最小样本数的差异:第二行(00:01)窗口内只有 2 个点,满足 Z-Score(min=2),但不满足 MAD 和 IQR(min=3)。
第二,同一个离群点(val=80),Z-Score 仅给出 2 分,而 MAD 给出 155.58、IQR 给出 136.5。这印证了前文提到的 Z-Score 自我稀释问题:80 这个值把均值和标准差一起抬高,使它相对于"被污染后的均值"反而没有偏离太多个标准差。MAD 与 IQR 基于中位数 / 分位数,离群点无法撼动中位数,因此它们能识别出该点的强异常。
结论很明确:识别单点离群时,应以 MAD 或 IQR 的结果为准,而非 Z-Score。
实战:直接过滤出异常行
计算出分数后,通常需要的不是完整的分数表,而是把异常行单独筛选出来。窗口函数不能直接写在 WHERE 中,因此用一个子查询包裹,在外层做过滤:
sql
SELECT * FROM (
SELECT
host,
ts,
val,
ROUND(anomaly_score_mad(val) OVER (
PARTITION BY host
ORDER BY ts
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
), 2) AS mad
FROM sensor_data
) WHERE mad > 3.0
ORDER BY host, ts;结果只保留异常行:
text
+-------+---------------------+------+--------+
| host | ts | val | mad |
+-------+---------------------+------+--------+
| web-1 | 2025-01-01 00:04:00 | 80 | 155.58 |
+-------+---------------------+------+--------+阈值 3.0 是一个常见的起点(大致对应"3 个标准差以外"的直觉),但并非固定值,需要根据数据的噪声水平调整。
窗口的选择同样关键
理解三个函数的差异固然重要,但实践中影响更大的往往是 OVER 子句中的窗口范围。上面的示例使用的是累积窗口:
sql
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW它从序列开头一直累积到当前行。优点是样本随时间增多、分数更稳定;缺点是较早的数据会持续参与计算,对缓慢的趋势漂移不敏感。
如果指标存在日内周期,或会随版本发布整体抬升,更适合使用滑动窗口,只考虑最近 N 个点:
sql
ROWS BETWEEN 4 PRECEDING AND CURRENT ROW这样"什么算正常"会跟随近期数据变化,较旧的数据自动移出窗口。此外,PARTITION BY host 不可省略——它保证每台主机、每个 series 各自独立计算,不会把一台机器的基线套用到另一台上。
小结
- 优先使用 MAD。 监控数据中单点尖刺最为常见,MAD 对其最敏感,且不易被离群点自身干扰。
- 告警阈值场景使用 IQR。 栅栏内一律 0 分的特性使阈值判断更清晰,可通过
k(建议先试 1.5)调整灵敏度。 - Z-Score 适合快速粗筛。 数据干净、只需粗略信号时使用,但它不擅长捕捉极端离群点。
- 过滤异常行 = 子查询 + 外层 WHERE。 窗口函数无法直接进入 WHERE,包裹一层即可解决。
- 先确定窗口,再选择函数。 累积窗口求稳,滑动窗口贴近近期基线;务必用
PARTITION BY隔开不同 series。
这三个函数都是纯统计方法,识别的是"相对于窗口内其他点的离群",不涉及趋势预测或周期性异常检测,后者需要更复杂的模型。但对于"指标突然跳变"这类占告警绝大多数的场景,一条 SQL 即可完成,无需为此单独维护一套数据管道。
这三个函数目前仍处于实验阶段,我们也会持续扩充异常检测函数的能力。如果你在使用中遇到问题,或者希望看到某种特定的异常检测方法,欢迎到 GitHub 上提 issue 与我们交流:GreptimeTeam/greptimedb Issues。
完整的参数说明与退化情况表见官方文档:异常检测函数 - GreptimeDB 文档。

