On this page
2025 年的上海世博馆里,阿里巴巴的夸克 AI 眼镜首次亮相,搭载通义千问大模型,支持实时导航和支付功能。中国电信的天翼 AI 眼镜能够识别180种语言,为文旅和政务服务提供即时翻译。在 WAIC 2025 的展馆中,40 余款大语言模型、50 多款 AI 终端设备集中展示,宣告着端侧 AI 时代的正式到来。
但在这些炫目的AI应用背后,一个更深层的技术革命正在悄然发生:如何让海量的实时数据在资源受限的边缘设备上高效流转?

端侧 AI 的数据洪流
智能设备正在成为真正的数据工厂。一辆智能汽车每天产生的数据可达 TB 级别,包括摄像头的视觉流、雷达的感知数据、CAN 总线的车辆状态信息,以及用户的语音交互记录。这些数据需要在毫秒级的时间窗口内完成采集、存储、分析和决策。
传统的"数据上云"模式在这里遭遇了前所未有的挑战。网络延迟让实时决策成为奢望,带宽成本让数据传输不堪重负,而隐私合规要求则让敏感数据的云端处理面临法律风险。端侧AI需要的是一种全新的数据处理范式:让数据在产生的地方就能得到智能处理。
传统的基于文件上传和大数据体系方案:
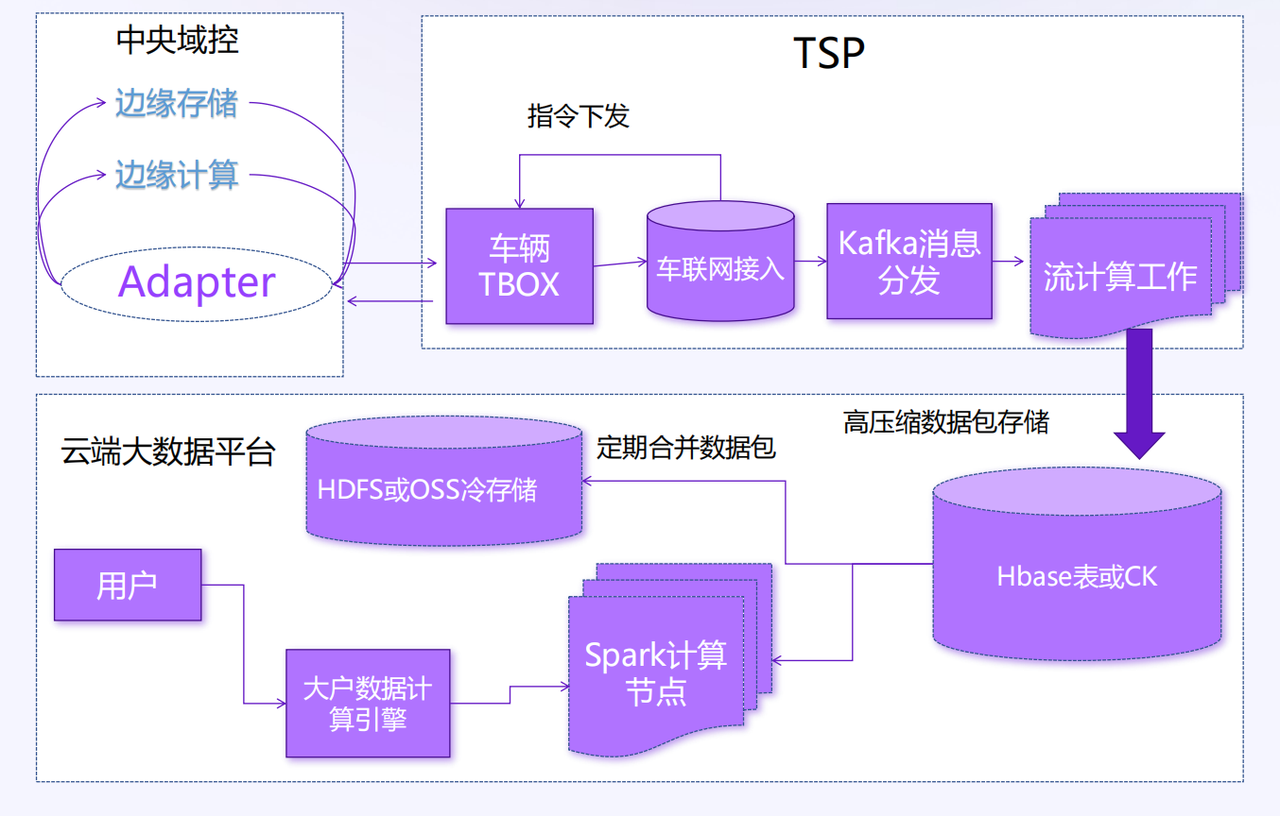
边缘计算的数据基础设施困境
问题的核心在于,现有的数据基础设施并非为边缘场景而生。
传统文件上传在端侧 AI 中压缩率低(如车载传感器数据仅 1:5,远低于 GreptimeDB Edge 的 1:30),上传后云端需解压缩、格式转换等,资源消耗大。高频数据场景下云端算力需求激增,运维成本较边缘处理高 40% 以上,阻碍端侧 AI 规模化。
以 SQLite 为代表的传统嵌入式数据库虽然轻量,但面对大规模时序数据时力不从心。在实际测试中,处理 1000 万行车载传感器数据时,SQLite 需要占用 1.6GB 的存储空间,而且不支持多线程并发写入,这在高频数据采集场景下成为明显的瓶颈(测试报告)。
更要命的是,传统数据库缺乏对时序数据特性的深度理解。车载传感器数据、工业设备监控数据、智能家居的环境数据,这些都具有明显的时间序列特征,需要专门的压缩算法、索引策略和查询优化。
GreptimeDB Edge的技术突破
正是在这样的背景下,专门针对边缘时序数据处理的 GreptimeDB Edge 应运而生。这不仅仅是一个数据库产品的优化,更是对边缘计算数据处理模式的重新思考。
在某头部新能源车企的量产环境中,GreptimeDB Edge 展现出了令人印象深刻的性能表现。在高通 8295 芯片平台上,它能够处理每秒 35 万个数据点的写入,CPU 占用率却不到单核的 3%,内存消耗仅 200 MB。这意味着即使在资源受限的车载环境中,数据库也不会与娱乐系统争夺计算资源。
更重要的是数据压缩能力的突破。通过列式存储和专门的时序数据压缩算法,GreptimeDB Edge 压缩率高达 30 倍(对比原始报文),极大降低了流量成本和云端存储成本。在实际量产场景中,1 G 的磁盘分区可以保存一周以上的数据。
边缘数据库面临闪存寿命挑战。特斯拉 2010-2018 年生产的 Model S 和 Model X 因 8GB 闪存卡耐久性问题导致媒体控制单元故障。GreptimeDB Edge 专为闪存优化设计,在保证存储检索性能的同时有效延长闪存使用寿命。
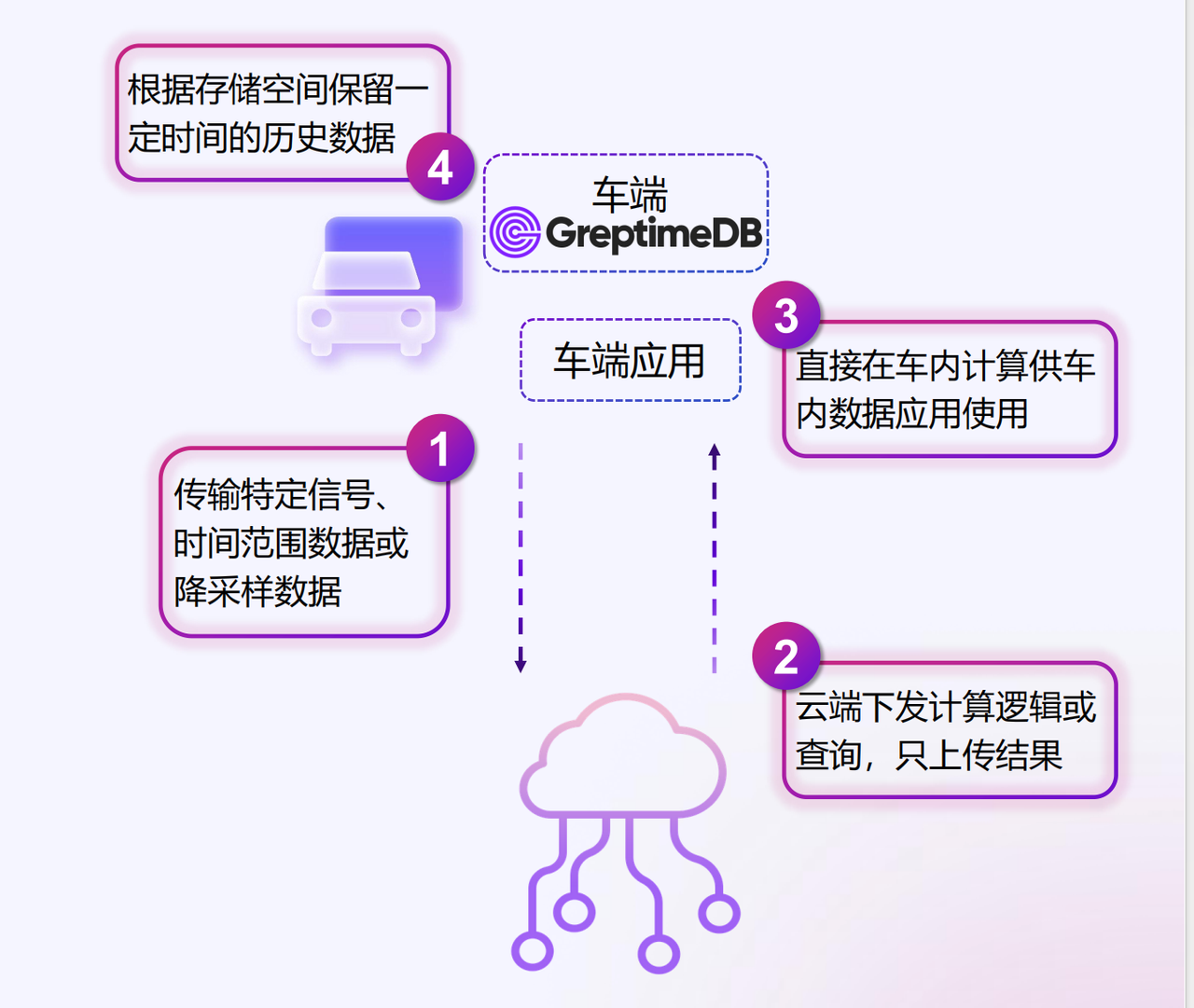
边云协同的新模式
GreptimeDB Edge 2.0 版本的发布标志着边缘数据处理进入了一个新阶段。新版本不仅支持传统的时序数据存储,还集成了流式计算引擎和日志处理能力,真正实现了"一个数据库,多种数据类型"的统一处理。
在实际应用中,这种设计哲学带来了显著的架构简化。车载系统不再需要部署多套数据处理组件,一个 GreptimeDB Edge 实例就能同时处理 CAN 总线的结构化数据、语音交互的日志数据,以及 A I模型的向量数据。数据在边缘完成初步处理和分析后,只有关键结果和压缩后的历史数据才会同步到云端,实现了真正的边云协同。
某新能源车企通过这种模式,将数据传输和存储成本至少降低了 50%,甚至做到数据不出车,完全本地化处理,仅将脱敏的处理结果出车。更重要的是,即使在网络信号较差的偏远地区,车辆的智能功能也能正常工作,因为关键的数据处理都在本地完成。
多模态数据的统一处理
端侧 AI 的另一个显著特点是多模态数据的融合处理。现代智能设备需要同时处理视觉、听觉、传感器等多种类型的数据,并且这些数据往往需要时间同步和关联分析。
GreptimeDB Edge 2.0 版本新增的向量数据类型支持,专门针对这一需求进行了优化。无论是摄像头的图像特征向量,还是语音识别的音频特征,都能在同一个数据库中高效存储和检索。这为边缘AI应用的开发提供了统一的数据基础设施,大大降低了系统复杂度。

实时流处理的边缘化
传统的流处理往往发生在云端,但端侧 AI 的实时性要求让这种模式不再适用。GreptimeDB Edge 2.0 集成的 Flow 引擎,让实时流处理能够直接在边缘设备上执行。
这种能力在智能制造场景中展现出巨大价值。生产设备的传感器数据可以在本地实时分析,异常情况能够在毫秒级时间内触发预警,而不需要等待数据传输到云端再返回结果。某工业客户通过这种实时边缘分析,将设备停机时间减少了 60% 以上。
开源生态的力量
值得注意的是,GreptimeDB 作为开源项目,其创新不仅来自核心团队,更受益于整个开源社区的贡献。从 Rust 语言的内存安全特性,到 Apache DataFusion 的查询引擎,再到 Arrow 格式的列式存储,整个技术栈都建立在成熟的开源基础之上。
这种开放的技术生态为端侧AI的发展提供了坚实的基础。开发者可以根据具体需求定制优化,企业用户也不用担心技术锁定的风险。
端侧 AI 数据处理的未来
从 WAIC 2025 的展示可以看出,端侧 AI 正在从概念走向大规模商用。但这场变革的成功,很大程度上取决于底层数据基础设施能否跟上应用需求的发展步伐。
GreptimeDB Edge 在边缘时序数据处理方面的创新,为这个问题提供了一个可行的解决方案。通过专门的架构设计、优化的存储引擎、以及边云协同的数据处理模式,它让端侧 AI 应用能够在资源受限的环境中高效运行。
更重要的是,这种创新代表了一种新的思维方式:不是简单地将云端技术小型化,而是从边缘计算的特性出发,重新设计整个数据处理架构。这或许才是端侧AI时代真正需要的技术革命。
当我们谈论端侧AI的未来时,算法模型的进步固然重要,但数据基础设施的创新同样关键。只有当数据能够在边缘设备上高效流转时,端侧 AI 才能真正释放其潜力,改变我们与智能设备交互的方式。
了解更多 GreptimeDB Edge 和端边云同步方案,请访问这里。