本页内容
💡 本篇文章所述需要在 GreptimeDB v0.15 前提下使用,请相关的用户尽快升级。
我们将在 v0.15 后发布一系列文章,已经发布的文章列表如下:
......
其他文章更新中,敬请期待。
引言
GreptimeDB 是一款开源、云原生的统一可观测性数据库,专为指标(metrics)、日志(logs)和链路追踪(traces)等数据而设计,能够在任何规模下提供从边缘到云端的实时洞察。作为一款现代化的可观测性数据库,GreptimeDB 针对不同的应用场景,提供了灵活高效的数据写入方案。其 Rust 客户端支持两种截然不同的写入方式:低延迟写入 API 和 高吞吐量的 Bulk Stream Insert API。
本文将重点介绍 v0.15 引入的 Bulk Stream Insert 这一高性能写入方式,全面解析其设计原理、使用方法、性能优化策略和生产环境中的最佳实践。无论您是在处理 ETL 数据管道、日志收集系统,还是执行大规模数据迁移,本文都将为您提供完整的实践指导。
写入方式概览
低延迟写入 API
适用场景: 实时应用、IoT 传感器和交互式系统
性能特点:
- 延迟:亚毫秒级
- 吞吐量:1k~10k 行/秒
- 内存占用:适当吞吐下内存低且恒定,高并发高吞吐可能会导致内存积压
- 网络模式:一请求一响应(Request-Response)
代码示例:
Rust
use greptimedb_ingester::api::v1::*;
use greptimedb_ingester::client::Client;
use greptimedb_ingester::helpers::schema::*;
use greptimedb_ingester::helpers::values::*;
use greptimedb_ingester::{database::Database, Result, ColumnDataType};
#[tokio::main]
async fn main() -> Result<()> {
// 连接到 GreptimeDB
let client = Client::with_urls(["localhost:4001"]);
let database = Database::new_with_dbname("public", client);
// 定义传感器数据 schema
let sensor_schema = vec![
tag("device_id", ColumnDataType::String), // 标签列
timestamp("ts", ColumnDataType::TimestampMillisecond), // 时间戳
field("temperature", ColumnDataType::Float64), // 数值字段
field("humidity", ColumnDataType::Float64), // 数值字段
];
// 创建实时数据
let sensor_data = vec![Row {
values: vec![
string_value("sensor_001".to_string()),
timestamp_millisecond_value(1234567890000),
f64_value(23.5),
f64_value(65.2),
],
}];
// 实时写入数据
let insert_request = RowInsertRequests {
inserts: vec![RowInsertRequest {
table_name: "sensor_readings".to_string(),
rows: Some(Rows { schema: sensor_schema, rows: sensor_data }),
}],
};
let start_time = std::time::Instant::now();
let affected_rows = database.insert(insert_request).await?;
let latency = start_time.elapsed();
println!("实时写入成功: {} 行数据,延迟: {:.1}ms",
affected_rows, latency.as_millis());
Ok(())
}高吞吐量 Bulk Stream Insert API
适用场景: ETL 操作、数据迁移、批处理和日志摄取
性能特征:
- 延迟:100~10_000毫秒(按批次处理)
- 吞吐量:>10k 行/秒
- 内存占用:稳定,有反压机制
- 网络模式:并行请求,流式传输,一张表独占一个流
核心优势:
- 并行处理:支持多个请求同时进行;
- 流式传输:基于 Apache Arrow Flight 流式协议;
- 压缩传输:支持 Zstd、Lz4 压缩算法;
- 异步提交:非阻塞式请求提交,支持反压。
快速开始指南
核心概念
在开始使用之前,了解几个核心概念:
- BulkInserter:写入器工厂,用于创建流式写入器(
BulkStreanmWriter); - BulkStreamWriter:绑定到特定表的高性能写入器;
- Schema 绑定:每个写入器只能写入一个表,确保类型安全;
- 异步提交:可以同时发送多个批次,提高吞吐能力。
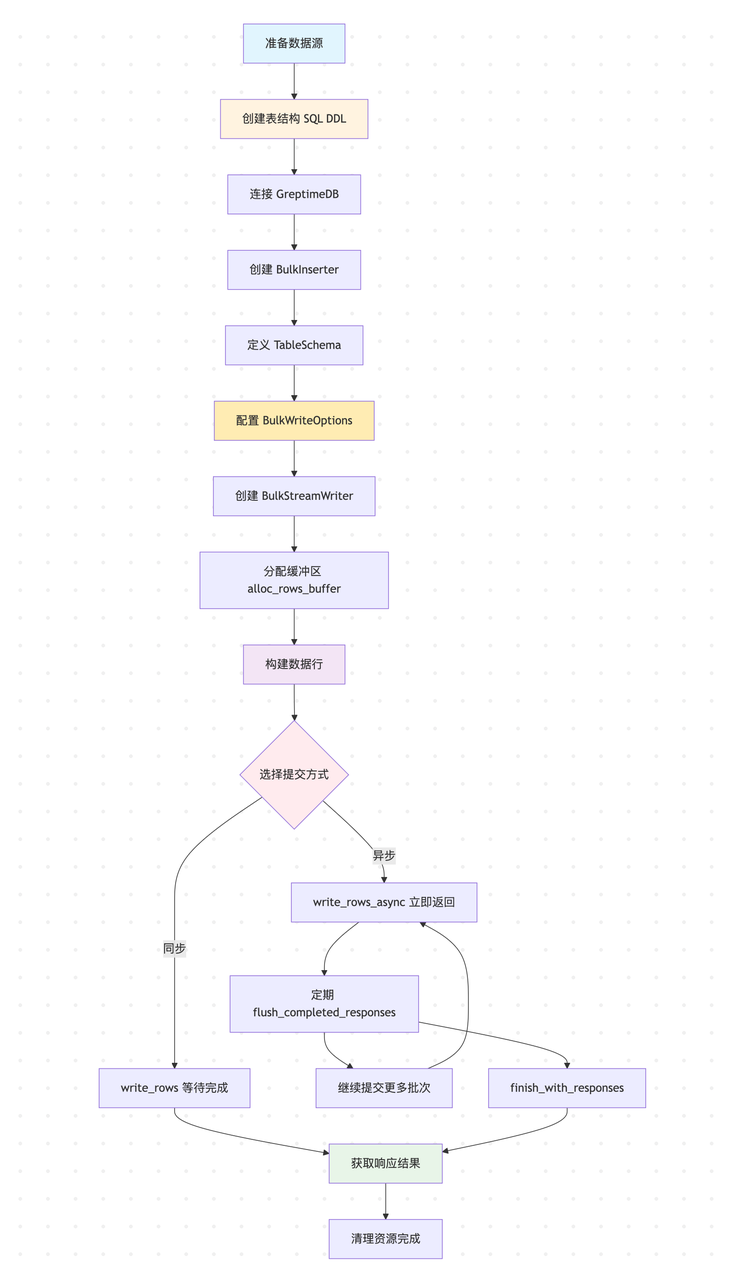
使用流程
- 预建表结构(必须先创建);
- 连接数据库并创建写入器;
- 准备批次数据并异步提交;
- 处理响应与资源清理。
工作流程图
关键组件详解
BulkInserter & BulkStreamWriter
- BulkInserte:负责创建和管理
BulkStreamWriter实例; - BulkStreamWriter:提供基于长连接的流式写入能力,具备批次缓冲、压缩、异步提交等特性。
BulkWriteOptions
配置选项,控制压缩、并发度和超时设置:
Rust
pub struct BulkWriteOptions {
pub compression: CompressionType, // 压缩算法,支持 Lz4 和 Zstd
pub timeout: Duration, // 单个请求超时时间
pub parallelism: usize, // 并发度
}高吞吐量写入实践
基础使用流程
1. 表创建要求
重要提醒: 与普通写入 API 不同,Bulk Stream Insert 不会自动创建表。用户必须事先使用 SQL DDL 创建表结构,不支持自动的 Schema 变更;还需要注意的是目前 Bulk API 不支持主键列(Tag),且要求写入的每一行数据必须包含所有的列。这些限制预计会在未来的版本中逐步解决,目前 Bulk API 还处于比较早期的阶段:
sql
-- 创建传感器数据表
CREATE TABLE sensor_data (
ts TIMESTAMP TIME INDEX,
sensor_id STRING,
temperature DOUBLE
)
ENGINE=mito
WITH(
append_mode = 'true',
skip_wal = 'true'
);2. Schema 定义和绑定
注意必须与数据库中的表结构完全匹配。
Rust
// 定义表结构模板(注意必须与实际表结构完全匹配)
let table_template = TableSchema::builder()
.name("sensor_data")
.build()
.unwrap()
.add_timestamp("ts", ColumnDataType::TimestampMillisecond) // index 0
.add_field("sensor_id", ColumnDataType::String) // index 1
.add_field("temperature", ColumnDataType::Float64); // index 23. 创建 Bulk Stream Writer
rust
let mut bulk_writer = bulk_inserter
.create_bulk_stream_writer(
&table_template,
Some(BulkWriteOptions::default()
.with_parallelism(8) // 最大并发度为 8
.with_compression(CompressionType::Zstd) // 启用 Zstd 压缩
.with_timeout(Duration::from_secs(60)) // 60 秒超时
),
)
.await?;数据写入方式
Bulk Stream Insert 提供三种数据写入方式,以下代码展示了同一个数据写入场景的三种不同实现:
rust
use greptimedb_ingester::{Row, Value, Result, BulkStreamWriter};
async fn demonstrate_three_approaches(bulk_writer: &mut BulkStreamWriter) -> Result<()> {
// 准备示例数据
let timestamp = 1234567890000i64;
let sensor_id = "sensor_001".to_string();
let temperature = 25.5f64;
// 创建缓冲区
let mut rows = bulk_writer.alloc_rows_buffer(10000, 1024)?;
// 方式一:快速 API - 性能最优,需要确保字段顺序正确
let row1 = Row::new().add_values(vec![
Value::TimestampMillisecond(timestamp),
Value::String(sensor_id.clone()),
Value::Float64(temperature),
]);
rows.add_row(row1)?;
// 方式二:安全 API - 字段名验证,避免字段顺序错误
let row2 = bulk_writer.new_row()
.set("ts", Value::TimestampMillisecond(timestamp))?
.set("sensor_id", Value::String(sensor_id.clone()))?
.set("temperature", Value::Float64(temperature))?
.build()?;
rows.add_row(row2)?;
// 方式三:索引 API - 性能与安全的平衡,通过索引设置字段
let row3 = bulk_writer.new_row()
.set_by_index(0, Value::TimestampMillisecond(timestamp))? // 索引 0: ts
.set_by_index(1, Value::String(sensor_id))? // 索引 1: sensor_id
.set_by_index(2, Value::Float64(temperature))? // 索引 2: temperature
.build()?;
rows.add_row(row3)?;
let response = bulk_writer.write_rows(rows).await?;
println!("写入成功: {} 行数据", response.affected_rows());
Ok(())
}提交方式对比
同步提交 vs 异步提交:
| 方法 | 调用方式 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|---|
write_rows() | 提交并等待完成 | 低频写入,简单场景 | 简洁,直接获取结果 | 阻塞等待,吞吐量受限 |
write_rows_async() + flush_completed_responses() | 批量提交 + 定期刷新 | 大批量,高并发 | 真正的并行处理,防止内存积累 | 需要管理响应和内存 |
rust
// 同步提交 - 简单场景
let response = bulk_writer.write_rows(rows).await?;
println!("同步写入: {} 行", response.affected_rows());
// 异步提交 - 批量提交 + 定期刷新
let mut batch_count = 0;
let batches: Vec<greptimedb_ingester::Rows> = vec![]; // 示例:预先准备的批次数据
for batch in batches {
bulk_writer.write_rows_async(batch).await?;
batch_count += 1;
// 每提交100个批次,刷新一次已完成的响应
if batch_count % 100 == 0 {
let completed = bulk_writer.flush_completed_responses();
println!("已完成 {} 个批次", completed.len());
}
}缓冲区参数说明
alloc_rows_buffer(capacity, row_buffer_size) 的两个参数作用:
capacity:每列预分配的行数容量,避免动态扩容带来的性能开销👇
- 建议值:根据批次大小设置,如 1000~50000;
- 过小:频繁扩容影响性能;
- 过大:占用过多内存。
row_buffer_size(行缓冲区大小):行缓冲作为行转列的 Buffer, 用于优化行转列的效率👇- 经验值:1024;
- 过小:频繁的行转列计算;
- 过大:浪费内存空间。
并行处理和响应管理
Bulk Stream Insert 异步提交
rust
use greptimedb_ingester::{Row, Value, Result};
async fn batch_async_submit(mut bulk_writer: greptimedb_ingester::BulkStreamWriter) -> Result<()> {
let batch_count = 1000;
let rows_per_batch = 1000;
let mut total_flushed_rows = 0usize;
// 第一阶段:快速提交所有批次
for batch_id in 0..batch_count {
let mut rows = bulk_writer.alloc_rows_buffer(rows_per_batch, 1024)?;
// 填充数据...
for i in 0..rows_per_batch {
let timestamp = 1234567890000 + ((batch_id * rows_per_batch + i) as i64 * 1000);
let sensor_id = format!("sensor_{:06}", (batch_id * rows_per_batch + i) % 1000);
let temperature = 18.0 + ((batch_id * rows_per_batch + i) as f64 * 0.03) % 25.0;
let row = Row::new().add_values(vec![
Value::TimestampMillisecond(timestamp),
Value::String(sensor_id),
Value::Float64(temperature),
]);
rows.add_row(row)?;
}
// 异步提交,不等待响应
let _request_id = bulk_writer.write_rows_async(rows).await?;
// 每100个批次刷新一次已完成的响应,防止内存积累
if (batch_id + 1) % 100 == 0 {
let completed = bulk_writer.flush_completed_responses();
let flushed_rows: usize = completed.iter().map(|r| r.affected_rows()).sum();
total_flushed_rows += flushed_rows;
println!("已刷新 {} 个已完成的响应,累计 {flushed_rows} 行数据", completed.len());
}
}
println!("所有批次提交完成,等待处理结果...");
// 第二阶段:关闭连接并收集剩余响应
let remaining_responses = bulk_writer.finish_with_responses().await?;
let remaining_rows: usize = remaining_responses.iter().map(|r| r.affected_rows()).sum();
let total_rows = total_flushed_rows + remaining_rows;
println!("Bulk Stream Insert 完成: {total_rows} 行数据");
println!("其中已刷新: {total_flushed_rows} 行,最终收集: {remaining_rows} 行");
println!("成功处理 {batch_count} 个批次");
Ok(())
}性能优化策略
并发度配置
rust
// 假设单实例单表写入,CPU cores = 4
// 网络绑定型 (Network-Bound):Bulk Stream Insert 主要等待网络传输
let network_bound_options = BulkWriteOptions::default()
.with_parallelism(16); // 推荐 8-16,充分利用网络带宽
// CPU 密集型 (CPU-Intensive):如果数据写入前需要大量计算处理
let cpu_intensive_options = BulkWriteOptions::default()
.with_parallelism(4); // 推荐 CPU 核心数
// 混合负载:根据实际瓶颈调整
let balanced_options = BulkWriteOptions::default()
.with_parallelism(8); // 在网络和 CPU 之间平衡压缩算法选择
rust
// Zstd: 更高压缩比,适合网络带宽有限的环境,可能会更消耗 CPU
let zstd_options = BulkWriteOptions::default()
.with_compression(CompressionType::Zstd);
// Lz4: 更快压缩速度,适合 CPU 资源有限的环境
let lz4_options = BulkWriteOptions::default()
.with_compression(CompressionType::Lz4);
// 无压缩: 最快速度,适合高速网络环境
let no_compression_options = BulkWriteOptions::default()
.with_compression(CompressionType::None);批次大小优化
rust
// 小批次:更低延迟,适合实时性要求高的场景
let small_batch_rows = bulk_writer.alloc_rows_buffer(1_000, 512)?;
// 大批次:更高吞吐量,适合批处理场景
let large_batch_rows = bulk_writer.alloc_rows_buffer(100_000, 2048)?;性能对比
为了更好地说明 Bulk API 的使用场景,我们在 GreptimeDB-ingester-rust 仓库中构建了一个简单的日志场景测试工具。
该工具提供了一个 LogTableDataProvider, 是为性能测试设计的高性能日志数据生成器,生成包含 22 个字段的合成日志数据,模拟真实分布式系统的日志场景,表结构如下:
表结构(22 字段)
sql
CREATE TABLE IF NOT EXISTS `benchmark_logs` (
`ts` TIMESTAMP(3) NOT NULL,
`log_uid` STRING NULL,
`log_message` STRING NULL,
`log_level` STRING NULL,
`host_id` STRING NULL,
`host_name` STRING NULL,
`service_id` STRING NULL,
`service_name` STRING NULL,
`container_id` STRING NULL,
`container_name` STRING NULL,
`pod_id` STRING NULL,
`pod_name` STRING NULL,
`cluster_id` STRING NULL,
`cluster_name` STRING NULL,
`trace_id` STRING NULL,
`span_id` STRING NULL,
`user_id` STRING NULL,
`session_id` STRING NULL,
`request_id` STRING NULL,
`response_time_ms` BIGINT NULL,
`log_source` STRING NULL,
`version` STRING NULL,
TIME INDEX (`ts`)
)
ENGINE=mito
WITH(
append_mode = 'true',
skip_wal = 'true'
);数据特点
关键特性:大型 log_message 字段
- 目标长度:1,500 字符(实际长度在 1,350~1,650 字符之间);
- 内容生成:基于模板的系统,根据日志级别生成不同类型的消息;
- 堆栈跟踪:ERROR 级别日志有 70% 的概率包含 3-8 行 Java 堆栈跟踪信息;
- 占位符替换:动态替换用户 ID、IP 地址、时间戳等变量。
字段基数/维度分布
高基数字段(近乎唯一)
trace_id,span_id:使用64位随机数生成 ;session_id,request_id:使用64位随机数生成;log_uid:基于时间戳 + 行索引,确保唯一性。
中等基数字段(约 10 万个值)
host_id/host_name:id格式为host-{0-99999}service_id/service_name:id格式为service-{0-99999}container_id/container_name:id格式container-{0-99999}pod_id/pod_name:id格式pod-{0-99999}cluster_id/cluster_name:id格式cluster-{0-99999}
低基数等字段不在这里一一列举。
数据分布特征
- 日志级别分布(真实生产模式)
INFO:84%,正常操作信息 ;DEBUG:10%,详细诊断信息;WARN:5%,警告情况;ERROR:1%,带堆栈跟踪的错误情况。
运行 Benchmark 测试
- 启动 GreptimeDB;
- 建表;
- 顺序启动 Bulk &Regular API Benchmark;
- 启动命令:
shell
# Bulk API Benchmark
cargo run --example bulk_api_log_benchmark --release
# Regular API Benchmark
cargo run --example regular_api_log_benchmark --release- 我的本地测试结果如下:
| API 类型 | 吞吐量 | 总耗时 | 平均延迟 | 提升幅度 |
|---|---|---|---|---|
| Bulk API | 155,099 rows/s | 12.90s | N/A (async) | +48.8% |
| Regular API | 104,237 rows/s | 19.19s | 683.46ms | 基准线 |
Bulk API Results
plain
=== GreptimeDB Bulk API Log Benchmark ===
Target rows: 2000000
Batch size: 100000
Parallelism: 8
→ Batch 1: 100000 rows processed (201010 rows/sec)
→ Batch 10: 1000000 rows processed (193897 rows/sec)
→ Batch 20: 2000000 rows processed (195556 rows/sec)
Final Results:
• Total rows: 2000000
• Total batches: 20
• Duration: 12.90s
• Throughput: 155090 rows/secRegular API Results
plain
=== GreptimeDB Regular API Log Benchmark ===
Target rows: 2000000
Batch size: 100000
→ Batch 1: 100000 rows processed, 100000 affected (125120 rows/sec, 641.73ms latency)
→ Batch 10: 100000 rows processed, 100000 affected (119781 rows/sec, 620.04ms latency)
→ Batch 20: 100000 rows processed, 100000 affected (104761 rows/sec, 775.90ms latency)
Final Results:
• Total rows: 2000000
• Total batches: 20
• Duration: 19.19s
• Throughput: 104232 rows/sec
• Average latency: 683.46ms详细的测试对比见这里。
总结
可以看到,在这个日志测试场景中
- 吞吐量方面 Bulk API(155099 rows/s)比 Regular API(104237 rows/s)快接近 50%。需要说明的是由于这个测试是在本机上,网络是本地环回接口,不考虑对网络带宽压力的情况,Regular API 没有开启 gRPC 压缩,Bulk API 则开启了 Arrow 编码的 Lz4 压缩,如果 Regular API 开启压缩的话吞吐话下降的会比较厉害,因为数据量实在是太大了,结果不放上来了,感兴趣的同学可以自行尝试;
- Regular API 更适合单个请求数据量较小的场景,比如一次写入 200~500 行,不对吞吐有较高的要求,可以得到较低的延时(建议手动尝试);
- Bulk API 则适合对吞吐要求更高,对延时有一定容忍的场景,其中延时也包括你需要在客户端自行积攒数据到一定量再一次写入到 DB。
那么具体如何选择呢?下面给出了一些场景作为参考👇
何时使用哪种 API
| 使用场景(特征) | 推荐 API | 理由 |
|---|---|---|
| 实时监控告警 | Regular API | 需要立即响应 |
| IoT 传感器数据 | Regular API | 小数据量,实时性重要 |
| 交互式仪表板 | Regular API | 用户期望即时反馈 |
| ETL 数据管道 | Bulk API | 大数据量,可容忍延迟 |
| 日志收集系统 | Bulk API | 高吞吐量,批处理 |
| 历史数据迁移 | Bulk API | 大量数据,一次性操作 |
在选择具体 API 时,请根据数据实时性要求、系统资源压力、网络带宽等因素综合评估。
GreptimeDB 提供的两种写入方式,在不同场景下各有优势。对于开发者来说,灵活组合使用这些写入能力,能够更好地满足实际业务需求,实现系统的可扩展性与高性能目标。

